So about a year ago, I decided I’d play around with Citra an open source emulator for 3DS and I thought it would be fun to document my adventures in reverse engineering some of the memory from Rune Factory 4 (Undub).
Citra has some sort of scripting support and I figured this would be interesting to play around with. Maybe also see if I can learn some new details about the undocumented farming systems in Rune Factory 4. There are also some other fun things I could dream up with this game scripting support that I hope to get to eventually.
I will note this started project before the release of the PC game, and using that would be an entirely different problem space. I really want to look into this undocumented emulator feature and figure out what I can do with it.
A Basic Script
https://github.com/citra-emu/citra/pull/4016
Okay, so how does this scripting thing work?
The documentation is almost nonexistent. It seems to be an IPC/RPC server, a networking connection between applications. The example script ‘citra.py’ provided with Citra has a total of two main functions.
def read_memory(self, read_address, read_size):
"""
>>> c.read_memory(0x100000, 4)
b'\\x07\\x00\\x00\\xeb'
"""
def write_memory(self, write_address, write_contents):
"""
>>> c.write_memory(0x100000, b"\\xff\\xff\\xff\\xff")
True
>>> c.read_memory(0x100000, 4)
b'\\xff\\xff\\xff\\xff'
>>> c.write_memory(0x100000, b"\\x07\\x00\\x00\\xeb")
True
>>> c.read_memory(0x100000, 4)
b'\\x07\\x00\\x00\\xeb'
"""
So we can read and write a block of memory. I was hoping for some more functionality, but we can still do a lot with this.
A full script just to read a simple value in memory might look something like this. (Ignoring any network error handling.)
from citra import Citra
c = Citra()
mem = c.read_memory(0x100000, 4)
print(mem)
# b'\x07\x00\x00\xeb'
Let’s extend these functions to make them easier to use, as directly using bytes in Python isn’t exactly intuitive.
class MyCitra(Citra):
def read_value(self, Address, Size = 1):
byt = self.read_memory(Address, Size)
return int.from_bytes(byt, byteorder='little', signed=False)
def write_value(self, Address, Value, Size = 1):
byt = int.to_bytes(Value, Size, byteorder='little', signed=False)
return self.write_memory(Address, byt)
These handy functions will convert the byte data to and from integer values, making these values more useful to a human.
Memory Layout
Now this kinda stumped me a bit, how do I know anything about the memory layout of this Rune Factory 4 game? Citra does not exactly provide an easy way to dump the memory. If my 3DS was modded, it sounds like I might be able to make memory dumps directly with the hardware.
I can use a memory searching program like Cheat Engine, but everything is going to be offset by a bit, and after some amount of investigation, I discovered that with how Citra stores it’s emulated memory pages, they tend to be fragmented, they won’t be sequential in memory. (Thank’s STL memory allocations…) I don’t know how easy it is to figure out the addresses, due to this being an emulated process, not the direct process running on the computer.
A Slow Solution
This is not a great idea. But the Citra scripting RPC server allows us to ask for a max of 32 bytes of data. So we can just make a loop, and ask for that amount of memory, again and again till eventually we are done…
Such a function could look like this:
from citra import MAX_REQUEST_DATA_SIZE
class MyCitra(Citra):
def dump_memory_slow(self, StartAddress, EndAddress, File = "MemDump.mem"):
print(f"Dumping Memory from: {StartAddress:x} to {EndAddress:x}" + \
f"({(EndAddress - StartAddress) / (1024 * 1024)} MB)")
Address = StartAddress
f = open(File, "wb")
while Address < EndAddress:
Mem = self.read_memory(Address, MAX_REQUEST_DATA_SIZE)
f.write(Mem)
if (Address % (1024 * 1024) == 0 and Address != 0):
print("#", end="", flush=True)
if (Address % (1024 * 1024 * 16) == 0 and Address != 0):
print(f" {Address / (1024 * 1024)} MB")
Address += MAX_REQUEST_DATA_SIZE
print()
return
So now if we want to dump the first 128 megabytes of memory to file, we can do something like this.
c = MyCitra()
c.dump_memory_slow(0, 128 * 1024 * 1024)
The main problem with this, is it’s stupidly slow. This 128 MB dump took me around 4 minutes. And it’s not even everything. If you know exactly where you are looking for and can grab just what you need, this would be fine. There is just too much overhead in the RPC server to make a complete memory dump in a reasonable time.
A Faster Memory Dump
Citra did at one time seem to have some debugging features, but they were removed some time ago. I have no idea why, they probably would be useful right now. Thankfully Citra is open source, so if I want access to the memory, I can probably poke things to make that happen.
I’m not going to bore you with the details (about the days I lost to figuring this out), but from examining the RPCServer code in ‘core\rpc\rpc_server.cpp’, I discovered that the main memory read function is ‘MemorySystem::ReadBlock’ part of ‘core/memory.cpp’.
void MemorySystem::ReadBlock(const Kernel::Process& process, const VAddr src_addr,
void* dest_buffer, const std::size_t size) {
auto& page_table = *process.vm_manager.page_table;
std::size_t remaining_size = size;
std::size_t page_index = src_addr >> PAGE_BITS;
std::size_t page_offset = src_addr & PAGE_MASK;
while (remaining_size > 0) {
const std::size_t copy_amount = std::min(PAGE_SIZE - page_offset, remaining_size);
const VAddr current_vaddr = static_cast<VAddr>((page_index << PAGE_BITS) + page_offset);
switch (page_table.attributes[page_index]) {
case PageType::Unmapped: { /* ... */ }
case PageType::Memory: {
DEBUG_ASSERT(page_table.pointers[page_index]);
const u8* src_ptr = page_table.pointers[page_index] + page_offset;
std::memcpy(dest_buffer, src_ptr, copy_amount);
break;
}
case PageType::Special: { /* ... */ }
case PageType::RasterizerCachedMemory: { /* ... */ }
default:
UNREACHABLE();
}
page_index++;
page_offset = 0;
dest_buffer = static_cast<u8*>(dest_buffer) + copy_amount;
remaining_size -= copy_amount;
}
}
So when you call read_memory from the provided python script, all the real action is happening in the case statement case PageType::Memory:. Here we can see that page_table.pointers is a simple collection of memory pages.
So I can make a new function where I’ll just loop through every page in the table, and if it’s of type “Memory”, write it’s data out to a file. Which looks like this:
FileUtil::IOFile file(path, "wb");
for (std::size_t page_index = 0; page_index < PAGE_TABLE_NUM_ENTRIES; page_index++) {
switch (page_table.attributes[page_index]) {
case PageType::Memory: {
DEBUG_ASSERT(page_table.pointers[page_index]);
const u8* src_ptr = page_table.pointers[page_index];
file.Seek(page_index * PAGE_SIZE, SEEK_SET);
if (file.WriteBytes(src_ptr, PAGE_SIZE) != PAGE_SIZE) {
throw std::runtime_error("Could not write to file " + path);
}
break;
}
}
}
Since I want to keep things simple for myself, I’ll use Citra’s Save State folder for output the memory dump, and since I’m already using the RPC server, I’ll just create a new server command to call my memory dump function.
Then with a little more cpp code to glue things together, I’ve added a way to call this from the python script, which I’ll omit for brevity, as I just did a stupid quick refactor one of the existing server calls.
Now I call my new python function like this:
c = MyCitra()
FileName = c.dump_memory()
print(f"Memory Dumped to {FileName}")
# Memory Dumped to 1613609829.mem
Citra’s lengthy compile times aside, this works and it’s super fast, only taking a fraction of a second to dump everything in emulated ram. But yikes, the memory dump for this game is 511 megabytes!
That can really add up if you make a lot of these. Which we are going to need if we want to search for comparisons.
There is actually a lot of dead space in these memory dumps so I did experiment with stuff like only saving pages that contained something and writing an index of where everything is in the dump, but that really complicates things for later, so in-the-end I found a much better solution to deal with the large memory dumps.
Windows has built in compression in it’s OS and you can enable this compression at the folder level. If you enable this feature on the save state folder, whenever one of these large memory dumps is created, 511 MBs easily compresses down to a manageable 20 MBs. Hooray! That’s like 4% of the original size.
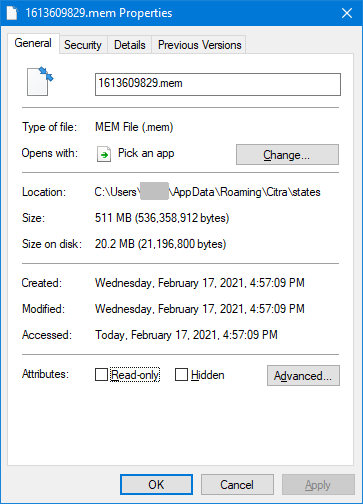
In hindsight a year after having done this, there seems like there might be a way to tell STL to allocate memory without fragmentation. But hey, my final solution works fine and makes the later stuff fairly easy. And probably the less I have to touch STL and Citra’s CPP code the better.
Anyway, all that work just to get a memory dump file to search. I haven’t even done anything fun yet. Next time I’ll poke around with these memory files.